


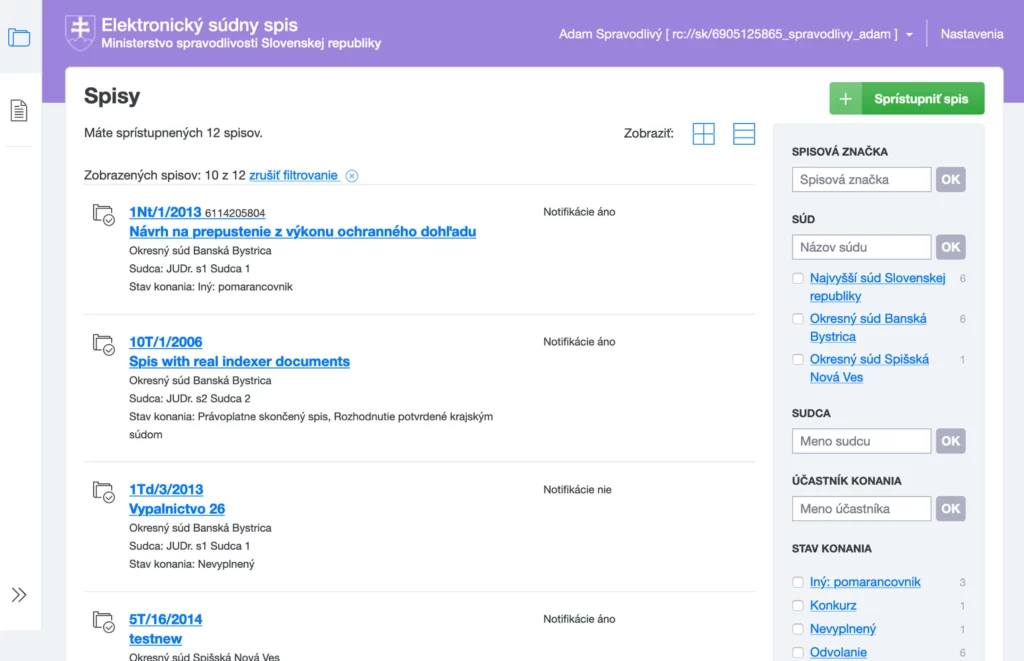
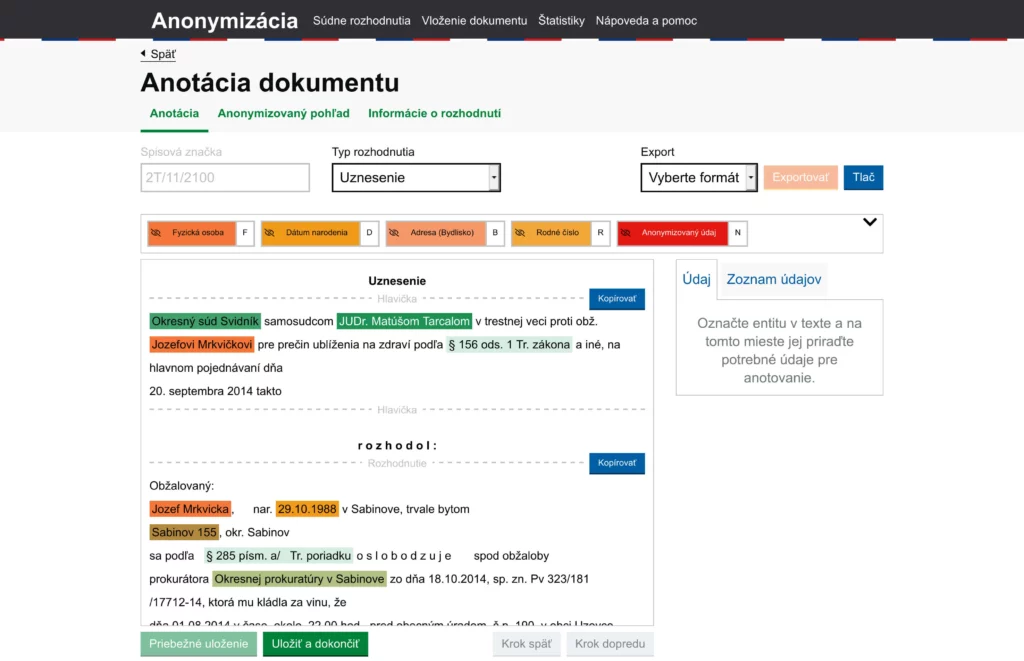
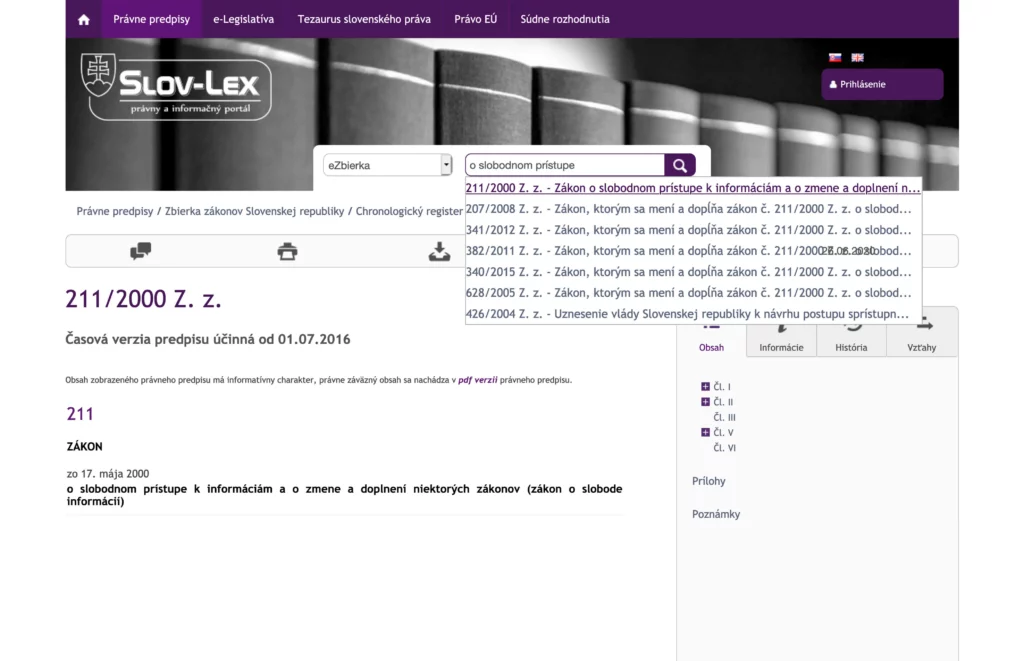
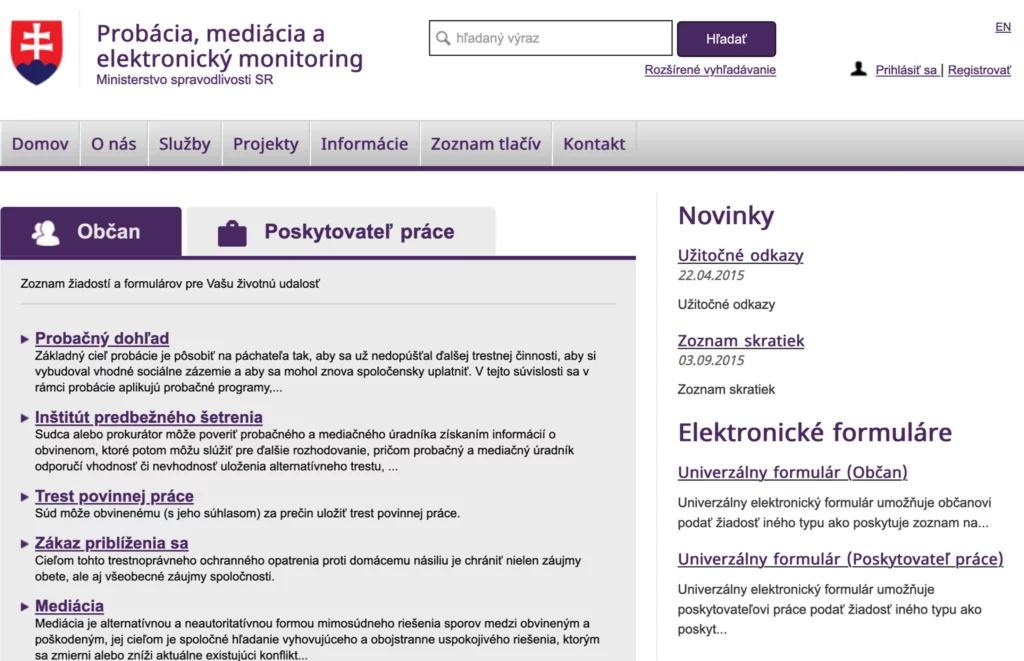



Špecializujeme sa na vyhľadávanie a spracovanie dát
v slovenskom jazyku.
Tvoríme používateľsky prívetivé agendové systémy.
Optimalizujeme a automatizujeme procesy vo verejnej správe.
Zameriavame sa na vývoj v Jave a JavaScripte.
Špecializujeme sa na vyhľadávanie a spracovanie dát v slovenskom jazyku.
Tvoríme používateľsky prívetivé agendové systémy.
Optimalizujeme a automatizujeme procesy vo verejnej správe.
Zameriavame sa na vývoj v Jave a JavaScripte.
Náš príbeh tvoríme od roku 2013. Partia kamarátov prišla s myšlienkou vývoja riešenia na vyhľadávanie a spracovanie dát v slovenskom jazyku.
Takto vznikol náš prvý vyhľadávací nástroj, okolo ktorého sme vybudovali viacero úspešných projektov a stredne veľkú slovenskú IT firmu.
Tvoríme Java a JavaScriptový software house, ktorý sa venuje vývoju riešení pre inteligentnú verejnú správu.
Pridaj sa k nám.
Sme partia ľudí, developeri, analytici, architekti, projektoví manažéri, testeri,
ktorí spolu tvoria, nielen pri tabuli, ale aj pri káve. Väčšina z nás je vo firme
veľmi spokojná a oceňuje dobrú atmosféru a individuálny prístup.
Otvárame nové projekty, preto hľadáme ďalších parťákov do tímu.
Budeme radi keď sa nám ozveš.
| Cookie | Dĺžka trvania | Popis |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |